我想要解决的问题是:在一辆车里有一个摄像头,我想知道车开得有多快。你显然不能看速度表,只能看视频片段本身。深度学习魔法应该能帮助我们。
数据
我有两个不同的视频。一个用于训练,另一个用于测试。训练视频有20399帧,测试视频有10797帧。视频下载地址:https://github.com/commaai/speedchallenge。下面是一些例子:

视频中的样本图像
训练视频的标签是a .txt文件,其中每一行对应于特定帧的速度。
方法
这个问题最有趣的地方是你的神经网络输入会是什么样子。仅从一个静态图像计算速度是不可能的。一种有效的方法是将两个或更多的图像堆叠在一起,或者像LSTM或Transformer那样连续地堆叠。另一个是计算光流,我决定用它。
什么是光流?它基本上是一种为每个像素计算矢量的方法,告诉你两幅图像之间的相对运动。有一个很棒的computerphile视频:https://www.youtube.com/watch?v=4v_keMNROv4,你可以了解更多细节。有一些“经典”的计算机视觉算法可以用来计算光流,但深度学习已经变得更好了(这一点也不奇怪)。那么什么是SOTA方法,让我们看看paperswithcode:

RAFT 看起来不错,它还有PyTorch的实现。我forked原始存储库,并使其更简单一些。我不需要训练,评估等等。我只会用它来推理。
计算光流
为了进行推断,网络将两幅图像拼接起来,并预测了一个维度为*(2, image_height, image_width)*的张量。如前所述,图像中的每个像素对应一个二维向量。我们将在实际训练中使用这些文件,因此我们将它们保存为.npy文件。如果你想象光流图像它会是这样的:

训练
记住我们训练的目的:
光流→模型→车速估计
我选择的模型是EfficientNet。我非常喜欢它,因为它的可扩展性。它有8个不同的版本供你选择,最大的一个,EfficientNet-B7仍然非常非常好。你可以从一个像B0这样的小变体开始,然后如果一切工作正常,你有一个足够好的GPU,你可以选择一个更大的。还有一个PyTorch库,我会使用它来非常容易地加载预先训练好的网络模型,地址:https://github.com/lukemelas/effecentnet-PyTorch。如果你打开[train.ipynb](https://github.com/sharifelfouly/vehicle-speed – estimate),你就可以看到训练是如何运作的。
我总是从B0开始,然后放大到B3,因为我的GPU只有6 GB内存。经过训练,我得到如下结果(loss为均方误差):
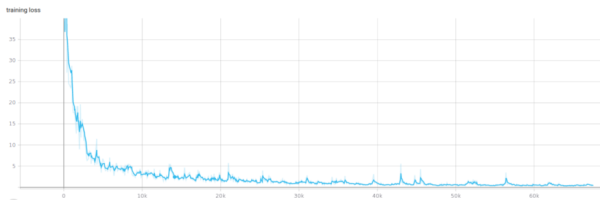
训练损失
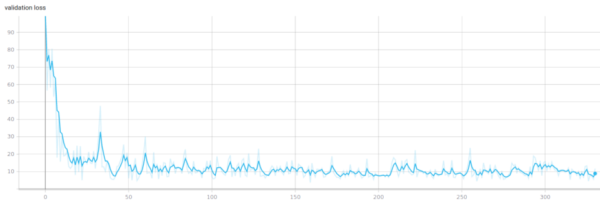
验证损失
很好,看起来一切都很正常!训练和验证损失都在降低,网络没有过拟合。
结果如下:

虽然不完美,但它确实有一些用
总结
我通常不太喜欢特征工程,但我认为在这种情况下它做得很好。下一步是尝试一些序列化的东西,比如Transformer或LSTM。
作者:AI公园_今日头条
原文链接:https://www.toutiao.com/i6913065469197189645/
转载请注明:www.ainoob.cn » 使用深度学习从视频中估计车辆的速度





