如何在机器学习中处理大型数据集
不是大数据…。

数据集是所有共享一个公共属性的实例的集合。 机器学习模型通常将包含一些不同的数据集,每个数据集用于履行系统中的各种角色。
当任何经验丰富的数据科学家处理与ML相关的项目时,将完成60%的工作来分析数据集,我们称之为探索性数据分析(EDA)。 这意味着数据在机器学习中起着重要作用。 在现实世界中,我们需要处理大量数据,这使得使用普通大熊猫进行计算和读取数据似乎不可行,这似乎需要花费更多时间,并且我们的工作资源通常有限。 为了使其可行,许多AI研究人员提出了一种解决方案,以识别处理大型数据集的不同技术和方式。
现在,我将通过一些示例来分享以下技术。 在这里为实际实施,我使用的是google Colab,它的RAM容量为12.72 GB。
让我们考虑使用随机数从0(含)到10(不含)创建的数据集,该数据集具有1000000行和400列。
执行上述代码的CPU时间和挂墙时间如下:

现在,让我们将此数据帧转换为CSV文件。
执行上述代码的CPU时间和挂墙时间如下:

现在,使用熊猫加载现在生成的数据集(将近763 MB),然后看看会发生什么。
当您执行上述代码时,由于RAM的不可用,笔记本电脑将崩溃。 在这里,我采用了一个相对较小的数据集,大小约为763MB,然后考虑需要处理大量数据的情况。 解决该问题的下一个计划是什么?
处理大型数据集的技术:
1.以块大小读取CSV文件:
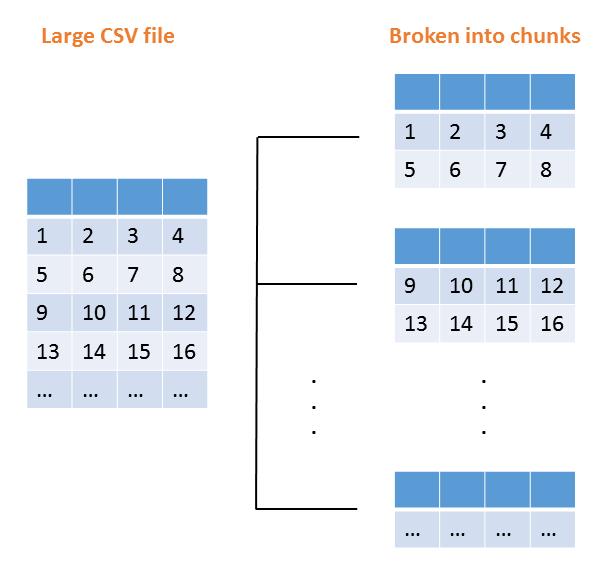
当我们通过指定chunk_size读取大型CSV文件时,原始数据帧将被分解成块并存储在pandas解析器对象中。 我们以这种方式迭代对象,并连接起来以形成花费较少时间的原始数据帧。
在上面生成的CSV文件中,此文件包含1000000行和400列,因此,如果我们读取100000行中的CSV文件作为块大小,则
执行上述代码的CPU时间和挂墙时间如下:

现在我们需要迭代列表中的块,然后需要将它们存储在列表中并连接起来以形成完整的数据集。
执行上述代码的CPU时间和挂墙时间如下:

我们可以观察到阅读时间的大幅改善。 这样,我们可以读取大型数据集并减少读取时间,有时还可以避免系统崩溃。
2.更改数据类型的大小:
如果要在对大型数据集执行任何操作时提高性能,则需要花费更多时间来避免此原因,我们可以更改某些列的数据类型的大小,例如(int64→int32),(float64→float32)以减少空间 它存储并保存在CSV文件中,以供进一步实施。
例如,如果我们在分块后将其应用于数据帧,并比较文件大小减少到一半之前和之后的内存使用情况,并且内存使用减少到一半,这最终导致CPU时间减少
数据类型转换前后的内存使用情况如下:
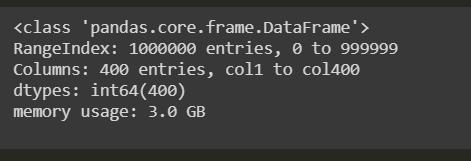
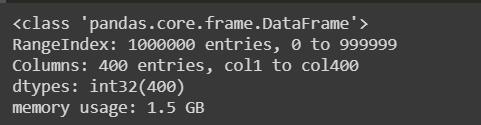
在这里,我们可以清楚地观察到3 GB是数据类型转换之前的内存使用量,而1.5 GB是数据类型转换之后的内存使用量。 如果我们通过计算数据帧前后的平均值来计算性能,那么CPU时间将减少,我们的目标就可以实现。
3.从数据框中删除不需要的列:
我们可以从数据集中删除不需要的列,以便减少加载的数据帧的内存使用量,这可以提高我们在数据集中执行不同操作时的CPU性能。
4.更改数据格式:
您的数据是否以CSV文件之类的原始ASCII文本存储?
也许您可以通过使用另一种数据格式来加快数据加载速度并使用更少的内存。 一个很好的例子是二进制格式,例如GRIB,NetCDF或HDF。 您可以使用许多命令行工具将一种数据格式转换为另一种格式,而无需将整个数据集都加载到内存中。 使用另一种格式可以使您以更紧凑的形式存储数据,以节省内存,例如2字节整数或4字节浮点数。
5.使用正确的数据类型减少对象大小:
通常,可以通过将数据帧转换为正确的数据类型来减少数据帧的内存使用量。 几乎所有数据集都包含对象数据类型,该对象数据类型通常为字符串格式,这对内存效率不高。 当您考虑日期,类别特征(如区域,城市,地名)时,它们会占用更多的内存,因此,如果将它们转换为相应的数据类型(如DateTime),则类别将使内存使用量比以前减少10倍以上 。
6.使用像Vaex这样的快速加载库:
Vaex是一个高性能Python库,用于懒惰的Out-of-Core DataFrame(类似于Pandas),以可视化方式浏览大型表格数据集。 它以每秒超过十亿(10 ^ 9)个样本/行的速度在N维网格上计算统计信息,例如平均值,总和,计数,标准差等。 可视化使用直方图,密度图和3d体积渲染完成,从而允许交互式探索大数据。 Vaex使用内存映射,零内存复制策略和惰性计算来获得优质性能(不浪费内存)。
现在,让我们在上面随机生成的数据集中实现vaex库,以观察性能。
1.首先,我们需要根据您使用的操作系统,使用命令提示符/ shell安装vaex库。
2.然后,我们需要使用vaex库将CSV文件转换为hdf5文件。
执行上述代码后,将在您的工作目录中生成一个dataset.csv.hdf5文件。 数据类型转换前后的内存使用情况如下:

可以看出,将CSV转换为hdf5文件花费了将近39秒,相对于文件大小而言,时间要短一些。
3.使用vaex读取hdf5文件:-
现在我们需要通过vaex库中的open函数打开hdf5文件。
观察完上面的代码后,如果我们看到输出,则看似花了697毫秒来读取hdf5文件,由此我们可以了解读取3GB hdf5文件的执行速度。 这是vaex库的实际优势。
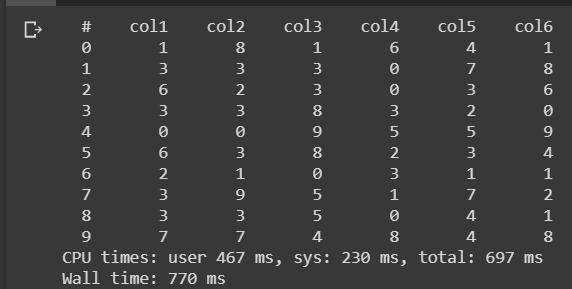
通过使用vaex,我们可以对大型数据帧执行不同的操作,例如
- 表达系统
- 超出核心数据帧
- 快速分组/聚合
- 快速高效的加入
如果您想探索有关vaex库的更多信息,请点击此处。
结论:
通过这种方式,我们可以在机器学习中处理大型数据集时遵循这些技术。
如果您喜欢这篇文章,请阅读这篇文章。如果您想在linkedin上与我联系,请点击下面的链接。
作者:闻数起舞_今日头条
原文链接:https://www.toutiao.com/i6841353190391153155/
转载请注明:www.ainoob.cn » 如何在机器学习中处理大型数据集






