
【51CTO.com快译】我们生活在日益分裂的世界。在世界上一些地区,种族和性别之间的差异和不平等现象在加剧。用于建模的数据大体上体现了数据源。世界可能有偏见,因此数据和模型可能会体现这一点。我们提出了一种方法,机器学习工程师可以轻松检查模型是否有偏见。现在我们的公平性工具仅适用于分类模型。
案例分析
为了表明dalex公平性模块(https://dalex.drwhy.ai/)的功能,我们将使用著名的德国信贷数据集(https://archive.ics.uci.edu/ml/datasets/statlog+(german+credit+data)为每个信贷申请者赋予风险。这个简单的任务可能需要使用可解释的决策树分类器。
- # imports
- import dalex as dx
- import numpy as np
- from sklearn.compose import ColumnTransformer
- from sklearn.pipeline import Pipeline
- from sklearn.preprocessing import OneHotEncoder
- from sklearn.tree import DecisionTreeClassifier
- # credit data
- data = dx.datasets.load_german()
- # risk is the target
- X = data.drop(columns='risk')
- y = data.risk
- categorical_features = ['sex', 'job', 'housing', 'saving_accounts', "checking_account", 'purpose']
- categorical_transformer = Pipeline(steps=[
- ('onehot', OneHotEncoder(handle_unknown='ignore'))
- ])
- preprocessor = ColumnTransformer(transformers=[
- ('cat', categorical_transformer, categorical_features)
- ])
- clf = Pipeline(steps=[
- ('preprocessor', preprocessor),
- ('classifier', DecisionTreeClassifier(max_depth=7, random_state=123))
- ])
- clf.fit(X, y)
- exp = dx.Explainer(clf, X, y)
一旦有了dx.Explainer,我们需要执行方法model_fairness(),以便它可以利用protected矢量来计算子组中的所有必要度量,该矢量是一个数组或列表,列出了表明每一个观察对象(个人)的性别、种族或国籍等方面的敏感属性。除此之外,我们需要指出哪个子组(即protected的哪个独特元素)具有最高特权,这可以通过privileged参数来完成,本例中将是较年长男性。
- # array with values like male_old, female_young, etc.
- protected = data.sex + '_' + np.where(data.age < 25, 'young', 'old')
- privileged = 'male_old'
- fobject = exp.model_fairness(protected = protected, privileged=privileged)
该对象有许多属性,我们不会遍历每一个属性,而是着重介绍一种方法和两个图。
那么,我们的模型是否有偏见?
这个问题很简单,但由于偏见的性质,答案将是要看情况。但是这种方法从不同的视角来度量偏见,因此确保没有任何有偏见的模型是漏网之鱼。要检查公平性,就得使用fairness_check()方法。
- fobject.fairness_check(epsilon = 0.8) # default epsilon
以下内容是来自上述代码的控制台输出。
- Bias detected in 1 metric: FPR
- Conclusion: your model cannot be called fair because 1 metric score exceeded acceptable limits set by epsilon.
- It does not mean that your model is unfair but it cannot be automatically approved based on these metrics.
- Ratios of metrics, based on 'male_old'. Parameter 'epsilon' was set to 0.8 and therefore metrics should be within (0.8, 1.25)
- TPR ACC PPV FPR STP
- female_old 1.006508 1.027559 1.000000 0.765051 0.927739
- female_young 0.971800 0.937008 0.879594 0.775330 0.860140
- male_young 1.030369 0.929134 0.875792 0.998532 0.986014
FPR(误报率)这个度量发现了偏见。上述输出表明无法自动批准模型(如上述输出中所述),因此得由用户来决定。我认为这不是公平的模型。较低的FPR意味着特权子组比无特权子组更容易出现误报。
详述fairness_check()
我们获得有关偏见、结论和度量比率原始DataFrame的信息。有几个度量:TPR(正阳性率)、ACC(准确度)、PPV(阳性预测值)、FPR(假阳性率)和STP(统计奇偶性)。这些度量来自每个无特权子组的混淆矩阵(https://en.wikipedia.org/wiki/Confusion_matrix),然后除以基于特权子组的度量值。有三种可能的结论:
- # not fair
- Conclusion: your model is not fair because 2 or more metric scores exceeded acceptable limits set by epsilon.
- # neither fair or not
- Conclusion: your model cannot be called fair because 1 metric score exceeded acceptable limits set by epsilon.It does not mean that your model is unfair but it cannot be automatically approved based on these metrics.
- # fair
- Conclusion: your model is fair in terms of checked fairness metrics.
DA真正公平模型不会超出任何度量,但是当真实值(目标)依赖敏感属性时,事情会变得复杂,并超出本文探讨的范围。简而言之,一些度量会不一样,但不一定会超出用户的阈值。如果您想了解更多,建议您阅读《公平性和机器学习》一书(https://fairmlbook.org/),尤其是第二章。
但有人会问:为何我们的模型不公平?我们基于什么依据来决定?
回答这个问题很棘手,但到目前为止判断公平性的方法似乎是最佳方法。每个子组的分数通常应接近特权子组的分数。从数学的角度来看,特权度量和无特权度量的分数之间的比率应接近1。该值越接近1,表明模型越公平。但为了稍微放宽该标准,这样表述更合理:
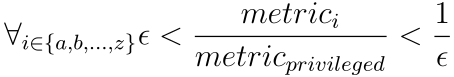
其中ε是介于0和1之间的值,它应该是该比率的最小可接受值。默认情况下,它是0.8,遵循招聘中常见的五分之四规则(80%规则)。很难在度量的公平和歧视差异之间找到一个非任意边界;检查度量的比率是否恰好为1毫无意义,因为如果比率为0.99会怎样? 这就是为什么我们决定选择0.8作为默认的ε,因为对于可接受的歧视程度而言,它是有形阈值的唯一已知值。当然,用户可以根据需要更改这个值。
偏见也可以绘出来
有两个偏见检测图可用(不过有更多的方法可以直观显示偏见)。
- fairness_check——直观显示fairness_check()方法
- metric_scores——直观显示metric_scores属性,它是度量的原始分数。
类型只需传递到plot方法的type参数。

- fbject.plot()
上图显示了与公平性检查输出相似的内容。度量名已改成更标准的公平性等效项,但是公式指出了我们引用的度量。上图很直观:如果条柱到达红色区域,表示度量超出基于ε的范围。条柱长度等效于| 1-M |,其中M是无特权度分数除以特权度量分数(因此就像之前的公平性检查一样)。
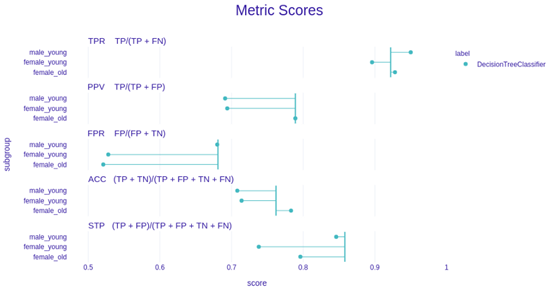
- fobject.plot(type=’metric_scores’)
度量分数图辅以公平性检查很好地表明了度量及其比率。在这里,这些点是原始的度量分数。垂直线表示特权度量分数。离那条线越近越好。
可以将多个模型放在一个图中,以便轻松相互比较。不妨添加几个模型,直观显示metric_scores:
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.linear_model import LogisticRegression
- from sklearn.preprocessing import StandardScaler
- # create models
- numeric_features = ['credit_amount', 'duration', 'age']
- numeric_transformer = Pipeline(steps=[
- ('scaler', StandardScaler())])
- categorical_transformer = Pipeline(steps=[
- ('onehot', OneHotEncoder(handle_unknown='ignore'))])
- preprocessor = ColumnTransformer(
- transformers=[
- ('cat', categorical_transformer, categorical_features),
- ('num', numeric_transformer, numeric_features)])
- clf_forest = Pipeline(steps=[('preprocessor', preprocessor),
- ('classifier', RandomForestClassifier(random_state=123, max_depth=4))]).fit(X,y)
- clf_logreg = Pipeline(steps=[('preprocessor', preprocessor),
- ('classifier', LogisticRegression(random_state=123))]).fit(X,y)
- # create Explainer objects
- exp_forest = dx.Explainer(clf_forest, X,y, verbose = False)
- exp_logreg = dx.Explainer(clf_logreg, X,y, verbose = False)
- # create fairness explanations
- fobject_forest = exp_forest.model_fairness(protected, privileged)
- fobject_logreg = exp_logreg.model_fairness(protected, privileged)
- # lets see their metric scores
- fobject.plot(objects=[fobject_forest, fobject_logreg], type = "metric_scores")
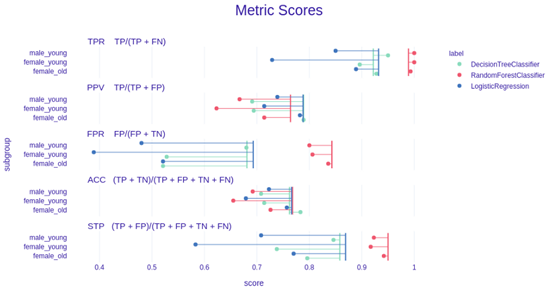
上述代码的输出。
现在不妨检查基于fairness_check的图:
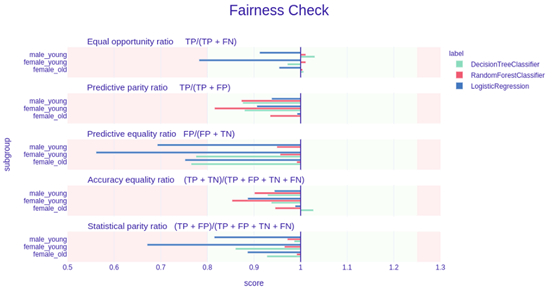
我们可以看到RandomForestClassifier在绿色区域内,因此就这些度量而言,它是公平的。另一方面,LogisticRegression在三个度量方面抵达红色区域,因此不能称之为公平的。
每个图都是交互式的,是使用python可视化包plotly绘制的。
结语
dalex中的公平性模块是确保模型公平的统一且可访问的方法。还有其他方法可以直观显示模型偏见,请务必查看一下!将来会增加缓解偏见的方法。长期计划是增添对 individual fairness和 fairness in regression的支持。
务必看一下。您可以使用以下命令来安装dalex:
- pip install dalex –U
原文标题:How to easily check if your Machine Learning model is fair?,作者:Jakub Wiśniewski
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】
作者:布加迪编译_51CTO
原文链接:http://ai.51cto.com/art/202012/638043.htm
转载请注明:www.ainoob.cn » 如何轻松检查你的机器学习模型是否公平?






