训练模型以预测谁能幸存下来。

[注意:请使用我们的完全交互式笔记本在此处自行构建模型。 无需任何编码经验。]
如果您像我,则需要玩一些东西然后”自己动手”才能真正理解它。 在这里,我们将举例说明机器学习的真正原理。
您将建立自己的机器学习模型,以预测乘客在泰坦尼克号上幸存的可能性。 该模型仅通过查看数据即可自行学习模式。
了解进行机器学习的步骤
遵循以下步骤:
- 加载数据并进行可视化探索;
- 为机器学习算法准备数据;
- 训练模型-让算法从数据中学习;
- 评估模型-查看它在从未见过的数据上的表现如何;
- 分析模型-查看需要多少数据才能正常运行。
要自己构建机器学习模型,请打开配套笔记本。 您将无需任何设置即可运行真实的机器学习代码-它可以正常工作。
了解机器学习工具
关于机器学习工具,有很多选择。 在本指南中,我们使用一些最受欢迎和功能最强大的机器学习库,即:
- Python:一种高级编程语言,以其易读性着称,是全球最受欢迎的机器学习语言。
- Pandas:Python库,将类似电子表格的功能引入该语言。
- Seaborn:一个用于绘制图表和其他图形的库。
- Scikit学习:Python的机器学习库,提供用于预测数据分析的简单工具。
- DRLearn:为此数据集构建的我们自己的DataRevenue Learn模块。
这些都是很好的工具,因为它们既适用于初学者,也适用于大型公司(如摩根大通)。
探索我们的数据集
我们将使用著名的”泰坦尼克号”数据集-稍有病态但引人入胜的数据集,其中包含泰坦尼克号上乘客的详细信息。 我们为每位乘客提供了大量数据,包括:
- 名称,
- 性别,
- 年龄,
- 机票舱位。
我们的数据采用行和列的标准形式,其中每一行代表一位乘客,每一列代表该乘客的属性。 这是一个示例:
- import pandas as pd
- from DRLearn import DRLearn
- titanic_dataset = pd.read_csv("titanic.csv", index_col=0)
- titanic_dataset.head()

> A few of the passengers that are in the titanic dataset. Source: Author
泰坦尼克号数据集中的一些乘客
可视化我们的数据集
机器学习模型很聪明,但是只能与我们提供给他们的数据一样聪明。 因此,重要的第一步是深入了解我们的数据集。
在分析数据时,一个很好的起点是检验假设。 持有头等舱机票的人更有可能生存,所以让我们看看数据是否支持这一点。
您可以在配套笔记本中查看并运行代码以产生这种可视化效果。
- DRLearn.plot_passenger_class(titanic_dataset)
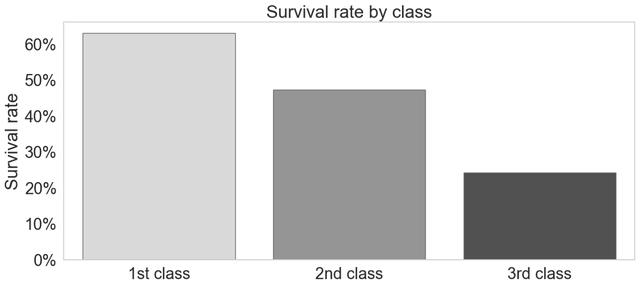
> 3rd class passengers had the worst survival rate, and 1st class passengers the best. Source: Autho
三等舱乘客的生存率最差,一等舱乘客的生存率最高。
头等舱中超过60%的人幸存,而三等舱中只有不到30%的人幸存。
您可能还听说过”妇女和儿童优先”一词。 让我们看一下性别与生存率之间的相互作用。
- DRLearn.plot_passenger_gender(titanic_dataset)
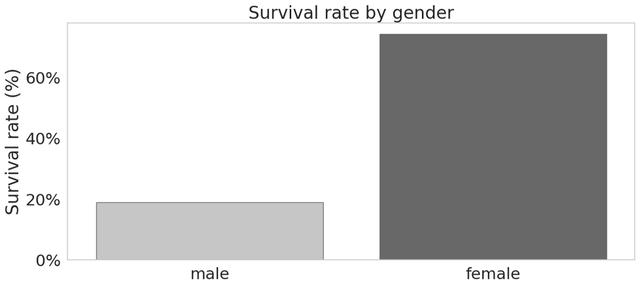
> Women were much more likely to survive than men. Source: Author
女人比男人更有可能生存。
同样,我们看到我们的假设是正确的。 超过70%的女性得以幸存,而只有大约20%的男性得以幸存。
就像这样,我们为数据集创建了两个基本的可视化。 我们可以在这里做更多的事情(对于生产机器学习项目,我们当然可以这样做)。 例如,多变量分析将显示当我们一次查看多个变量时会发生什么。
准备数据
在将数据输入到机器学习算法以训练模型之前,我们需要使其对我们的算法更有意义。 我们可以通过忽略某些列并重新格式化其他列来做到这一点。
忽略无用的列
我们已经知道,旅客的机票号码与他们的生存机会之间没有任何关联,因此我们可以显式忽略该列。 我们先删除它,然后再将数据输入模型。
重新格式化我们的数据
一些功能很有用,但不是原始形式。 例如,标签” male”(男性)和” female”(女性)对人类有意义,但对喜欢数字的机器没有意义。 因此,我们可以将这些标记分别编码为” 0″和” 1″。
selected_features, target = DRLearn.extract_features(titanic_dataset)selected_features.sample(5)
一旦准备好数据集,该格式将对机器更友好。 我们在下面提供了一个示例:我们消除了许多无用的列,而剩下的所有列都使用数字。
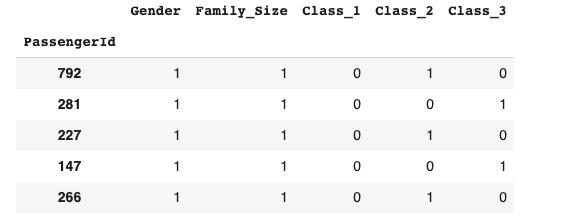
> After preparing the dataset it’s simpler and now ready for machine learning. Source: Author
准备完数据集后,它变得更简单了,现在可以进行机器学习了。
将数据集一分为二
现在我们需要训练我们的模型,然后对其进行测试。 就像给小学生提供测试题作为家庭作业的示例,然后给出考试条件下看不见的问题一样,我们将在一些数据上训练机器学习算法,然后查看其在其余数据上的表现如何。
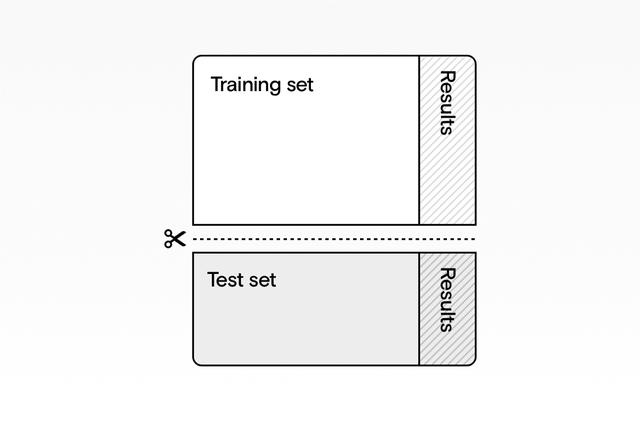
> We split our dataset: One part for training the model, and one part for testing it. Source: Author
我们拆分了数据集:一部分用于训练模型,另一部分用于测试模型。
- X_train, X_test, y_train, y_test = DRLearn.split_dataset(selected_features, target, split=0.2)
让我们训练模型!
现在开始有趣的部分! 我们会将训练数据输入模型中,并要求其查找模式。 在这一步中,我们为模型提供数据和所需的答案(无论乘客是否幸存)。
该模型从该数据中学习模式。
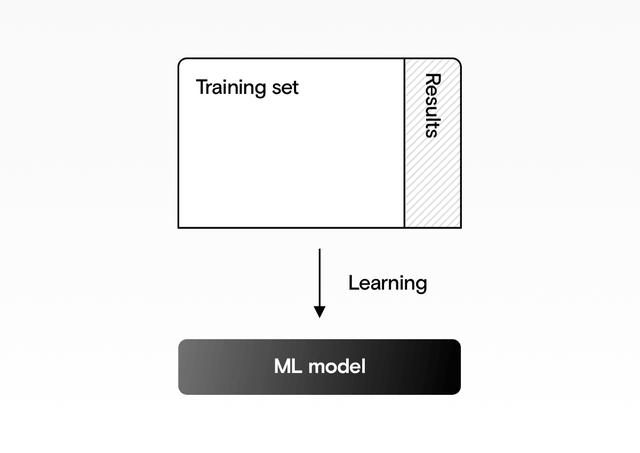
> Our machine learning model is trained on the Training set. Source: Author
我们的机器学习模型在训练集中进行训练。
- model = DRLearn.train_model(X_train, y_train)
测试我们的模型
现在,我们可以通过仅在数据集另一半中提供乘客的详细信息来测试模型,而无需给出答案。 该算法不知道这些乘客是否幸免于难,但是它将尝试根据从训练中学到的知识进行猜测。
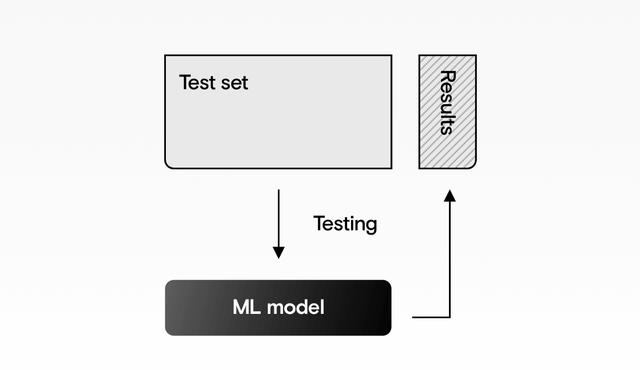
> Testing how well our machine learning model works by asking it to predict the results on the test
通过要求我们的机器学习模型预测测试数据的结果来测试其性能如何。
- DRLearn.evaluate_model(model, X_test, y_test)
分析我们的模型
为了更好地了解我们的模型如何工作,我们可以:
- 看看它最依赖哪些功能进行预测;
- 看看如果我们使用更少的数据,其准确性将如何变化。
第一个可以帮助我们更好地了解我们的数据,第二个可以帮助我们了解是否值得尝试获取更大的数据集。
了解我们的模型发现的重要内容
机器学习知道并非所有数据都同样有趣。 通过对特定细节进行加权,可以做出更好的预测。 下面的权重表明,性别是迄今为止预测生存率的最重要因素。
- DRLearn.explain_model(model, X_train)
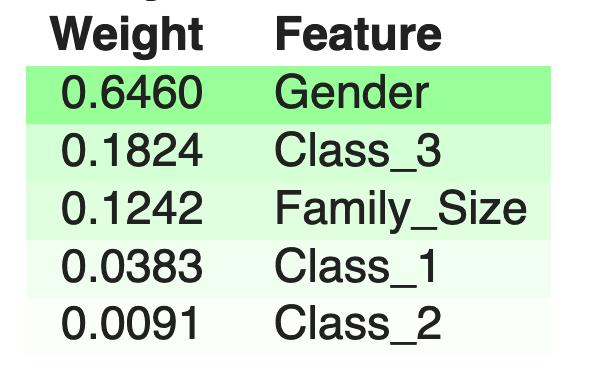
> Our model relies mostly on gender, a bit on whether the passenger was in 3rd class or not and on t
我们的模型主要取决于性别,有点取决于乘客是否属于三等舱以及其家庭人数。
我们还可以查看算法在预测特定乘客的生存时注意哪些数据方面。 下面我们看到一个算法认为很可能幸存的乘客。 它特别注意以下事实:
- 乘客不在三等舱;
- 乘客是女性。
由于该乘客也不属于头等舱,因此略微降低了生存的机会,因此最终生存预测为93%。
- model_interpretation = DRLearn.interpret_model(model, X_test, y_test)
- passenger_number = 3
- DRLearn.analyze_passenger_prediction(model_interpretation, X_test, passenger_number)
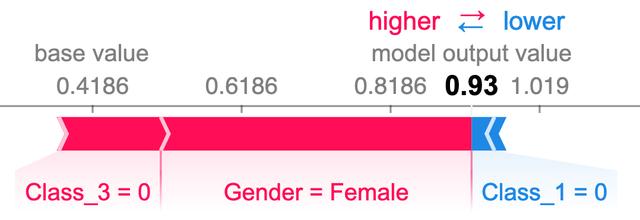
> How the model made a prediction for one particular passenger. She had a high survival rate because
该模型如何为一名特定乘客做出预测。 她的成年率很高,因为她是女性而不是三等班。
了解数据量如何影响我们的模型
让我们对模型进行多次训练,看看随着数据量的增加它可以改善多少。 在这里,我们同时绘制了训练得分和测试得分。 后者更有趣,因为它告诉我们模型在看不见的数据上的表现如何。
训练得分可以被认为是”公开考试”:该模型已经看到了答案,因此看起来比”测试得分”要高,但是该模型更容易对在测试过程中看到的数据表现良好 训练阶段。
- DRLearn.visualise_training_progress(model, X_train, y_train, X_test, y_test)
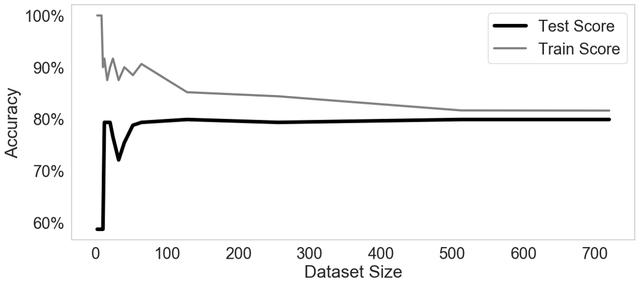
> More data makes our model better (test score). But after ~500 data points the improvement is minim
更多数据使我们的模型更好(测试分数)。 但是,在大约500个数据点之后,改进很小。
在这里,我们看到模型拥有的数据越多,其性能就越好。 在开始时这会更加明显,然后添加更多数据只会带来很小的改进。
机器学习模型不必是”黑匣子”算法。 模型分析可帮助我们了解它们如何工作以及如何改进它们。
结论
就是这样-您已经建立了自己的机器学习模型。 现在,您将能够:
- 了解数据科学团队的日常工作;
- 与您的数据科学或机器学习团队更好地沟通;
- 了解机器学习最能解决哪些问题;
- 意识到机器学习毕竟不是那么令人生畏。
机器学习的复杂部分涉及构建和扩展定制解决方案的所有细节。 这正是我们的专长。因此,如果您需要后续步骤的帮助,请告诉我们。
作者:闻数起舞_今日头条
原文链接:https://www.toutiao.com/i6839738072859410955/
转载请注明:www.ainoob.cn » 机器学习的工作原理-代码示例





