
本指南适用于任何对机器学习(Machine Learning,ML)感兴趣但不知道从何开始的人。
我们的目标是让任何人都可以理解,这意味着文中会有很多概述。但谁在乎呢?如果能使一些人对机器学习更感兴趣,我们将倍感欣慰。
什么是机器学习?
机器学习的概念是用一些通用算法告诉你关于一组数据的一些有趣的事情,而不需要你编写任何特定于问题的自定义代码。你不需要编写代码,而是将数据提供给通用算法,它将根据数据构建自己的逻辑。
例如,其中一种算法是分类算法。它可以将数据放入不同的组中。同样的分类算法可以用于识别手写数字,也可以用于将电子邮件分为垃圾邮件和非垃圾邮件,却不需要改变一行代码。使用相同的算法,但输入不同的训练数据,算法就会产生不同的分类逻辑。
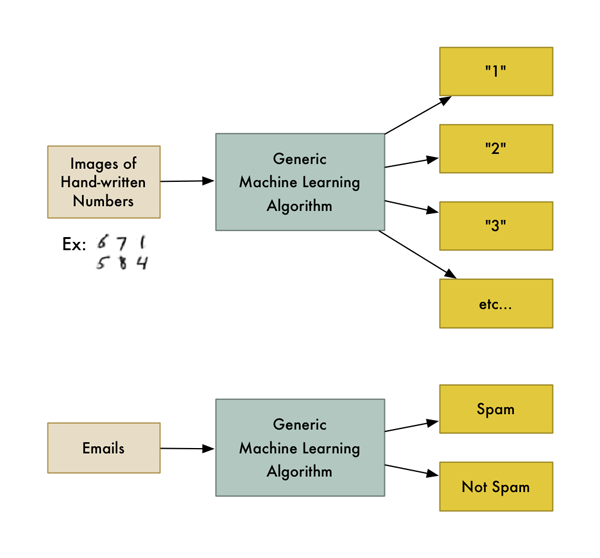
这种机器学习算法是一个黑箱,可以被用于许多不同的分类问题。
“机器学习”是一个涵盖了大量这类通用算法的总称。
两种机器学习算法
你可以将机器学习算法分为两大类——监督学习和无监督学习。区别很简单,但非常重要。
监督学习
假设你是一个房地产经纪人。你的业务正在增长,因此你聘请了一批新的实习生来帮助你。但是有一个问题:你能够随便看一下房子就能对房子的价格有一个很好的估计,但是你的实习生没有你的经验,所以他们不知道该如何定价。
为了帮助你的实习生(也许还能为你腾出时间去度假),你决定写一个小应用程序,根据你所在地区的房子的大小、社区等,以及类似房屋的售价来估算房屋的价格。
因此,每当有人在你所在城市出售房屋,你都需要记录下来,持续 3 个月。对于每套房子,你都要记录大量细节:卧室的数量、平方英尺为统一单位的面积、社区等。但最重要的是,你要记录最终的销售价格:
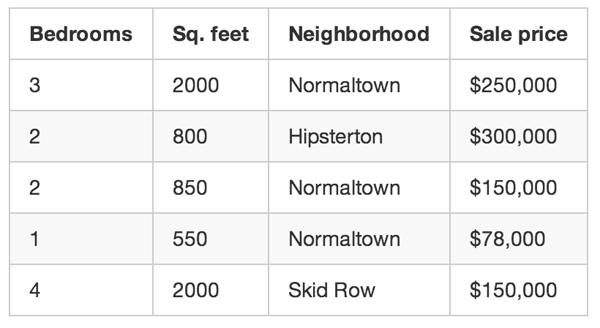
这是我们的“训练数据”。
利用这些训练数据,我们想创建一个程序,可以估算出所在地区其他房屋的价格:

我们想用训练数据来预测其他房屋的价格
这就是监督学习。你知道每套房子卖多少钱,换句话说,你知道问题的答案,并且可以从那里逆向计算出逻辑。
为了构建应用程序,你需要把每套房子的训练数据输入到你的机器学习算法中。该算法会尝试找出需要做什么样的数学运算才能算出数字。
这类似于拥有数学考试的答案,但是中间的运算符号都被擦去了:
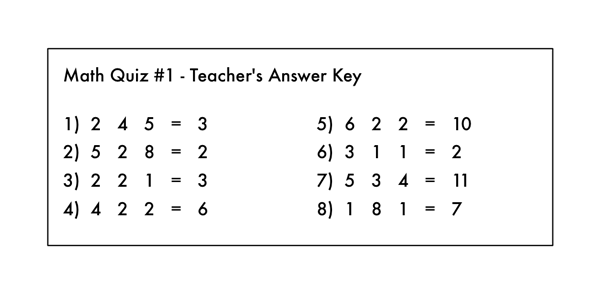
一个狡猾的学生擦掉了老师的答案上的算术符号!
从这里,你能得出考试中的数学问题是什么吗?你需要知道你应该用左边的数字“做点什么运算” 来得到右边的每个答案。
在监督学习中,就是让计算机为你计算这种关系。一旦你知道解决这组特定的问题需要什么数学知识,你就可以回答任何同类型的问题!
无监督的学习
让我们回到最初房地产经纪人的例子。如果你不知道每套房子的售价怎么办?即使你只知道每套房子的大小、位置等,你仍然可以做一些非常酷的事情。这就是无监督学习。
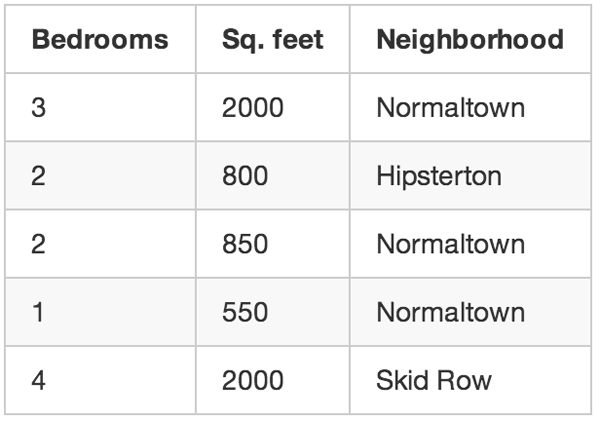
即使不想预测未知数字(比如价格),你仍然可以用机器学习做些有趣的事情。
这有点像是有人给你一张纸,纸上是数字列表,然后说:“我真的不知道这些数字有什么意思,但也许你能搞清楚是否有模式、分组或其他东西,祝你好运!”
那么用这些数据能做些什么呢?首先,你可以使用算法自动识别数据中的不同细分市场。也许你会发现,当地大学附近的购房者确实很喜欢有很多卧室的小房子,但是郊区的购房者更喜欢有很多平方英尺的三居室的房子。了解这些不同类型的客户有助于指导你的营销工作。
你能做的另一件很酷的事情是自动识别出任何与其他地方截然不同的住宅。也许那些离群的房子是豪宅,你可以把最好的销售人员集中在那些地区,因为他们能给出更多的佣金。
监督学习是我们将在这篇文章的其余部分重点关注的内容,但这并不是因为无监督学习不那么有用或不太有趣。事实上,随着算法的改进,无监督学习正在变得越来越重要,因为它可以在不需要给数据贴上正确答案标签的情况下使用。
附注:还有很多其他类型的机器学习算法,但现在已经是一个很好的开端。
这很酷,但是能够估算房价真的算作“学习”吗?
作为一个人,你的大脑几乎可以处理任何情况,并且是在没有任何明确指示的情况下学习如何处理这种情况。如果你长时间卖房子,你会本能地“察觉”到房子的合适价格、出售房子的最佳方式、感兴趣的客户类型等。强人工智能研究的目标就是能够用计算机复现这种能力。
然而目前的机器学习算法还不够好,它们只在关注一个非常具体且有限的问题时才起作用。在这种情况下,“学习”的一个更好的定义可能是“根据一些实例数据,找出解决特定问题的方程式”。
不幸的是,“机器根据一些实例数据计算出方程来解决特定的问题”并不是一个很好的名字。所以我们最终仍以“机器学习”命名。
当然,如果你在未来 50 年后读到这篇文章,并且我们已经找到了强人工智能的算法,那么这篇文章都会显得有点古怪。
让我们来写一写这个程序!
那么,如何编写程序来估算上面的例子中房子的价格呢?在进一步阅读之前,请考虑一下。
如果你对机器学习一无所知,你可能会试着写出一些估算房屋价格的基本规则,就像这样:
- def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
- price = 0
- # In my area, the average house costs $200 per sqft
- price_per_sqft = 200
- if neighborhood == "hipsterton":
- # but some areas cost a bit more
- price_per_sqft = 400
- elif neighborhood == "skid row":
- # and some areas cost less
- price_per_sqft = 100
- # start with a base price estimate based on how big the place is
- price = price_per_sqft*sqft
- # now adjust our estimate based on the number of bedrooms
- if num_of_bedrooms == 0:
- # Studio apartments are cheap
- priceprice = price — 20000
- else:
- # places with more bedrooms are usually
- # more valuable
- priceprice = price + (num_of_bedrooms * 1000)
- return price
如果你花几个小时来研究,可能会得到一些有用的东西。但你的程序永远不会完美,而且随着价格的变化,它将很难维持。
如果计算机能帮你实现这个功能不是更好吗?只要返回正确的数字,谁在乎函数究竟做了什么:
- def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
- price = <computer, plz do some math for me>
- return price
考虑这个问题的一种方式是,把价格看成是一道美味的炖菜,配料是卧室的数量、面积和社区。如果你能算出每种成分对最终价格的影响程度,也许就能算出每种成分在最终价格中所占的确切比例。
这会把你原来的函数(那些疯狂if和else的函数)简化成这样:
- def estimate_house_sales_price(num_of_bedrooms, sqft,neighborhood):
- price = 0
- # a little pinch of this
- price += num_of_bedrooms * .841231951398213
- # and a big pinch of that
- price += sqft * 1231.1231231
- # maybe a handful of this
- price += neighborhood * 2.3242341421
- # and finally, just a little extra salt for good measure
- price += 201.23432095
- return price
注意这些魔法数字: .841231951398213、1231.1231231、2.3242341421 和 201.23432095。这些是我们的权重。如果能计算出适用于每套房子的完美权重,我们的函数就能预测房价!
计算最佳权重的一个愚蠢方法是这样的:
第1步:
将每个初始权重设置为1.0:
- def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
- price = 0
- # a little pinch of this
- price += num_of_bedrooms * 1.0
- # and a big pinch of that
- price += sqft * 1.0
- # maybe a handful of this
- price += neighborhood * 1.0
- # and finally, just a little extra salt for good measure
- price += 1.0
- return price
第2步:
通过函数运行你所知道的每一栋房子,看看这个函数离预测到每一套房子的正确价格有多远:
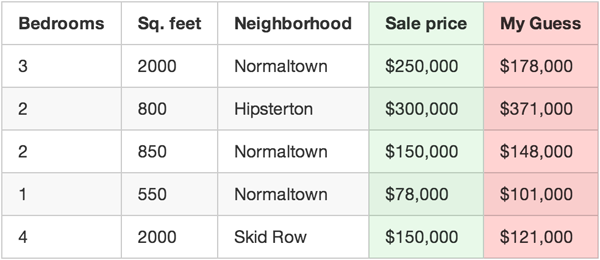
使用你的函数为每套房子预测价格
例如,如果第一套房子实际上卖了 25 万美元,但你的函数预测它卖了 17.8 万美元,那么这套房子的售价就少了 7.2 万美元。
现在把你的数据集里每套房子的售价差额平方相加,假设你的数据集中有 500 套房子的销售数据,你的函数计算的每套房子售价差额的平方的总和是 86,123,373 美元。这就是当前函数的“错误”程度。
现在,把总和除以 500,得到每套房子的平均差价。将这个平均错误量称为函数的成本(cost)。
如果你能通过调整权值使这个成本为零,你的函数就完美了。这意味着,在每种情况下,你的函数都能够根据输入的数据完美地猜测房屋的价格。这就是我们的目标:通过尝试不同的权重值使成本尽可能低。
第3步:
对每一个可能的权重组合重复第2步。最后选择使成本最接近于零的权重组合。当你找到合适的权重时,问题就解决了!
头脑风暴时间
很简单,对吧?回想一下你刚才都做了什么。你取了一些数据,通过三个通用的、非常简单的步骤输入数据,最后得到一个可以预测你所在地区的任何房子的价格的函数。
但还有一些事实会让你大吃一惊:
过去40年来,在许多领域(如语言学/翻译)进行的研究表明,这些“搅拌数字炖汤”(我刚编好的词)的通用学习算法可以实现真正的人为试图得到的明确规则方法。机器学习的“愚蠢”方法最终击败了人类专家。
最后得到的函数是完全愚蠢的。它甚至不知道“平方英尺”或“卧室”是什么。它所知道的是,它需要加入一些数字来得到正确的答案。
你很可能不知道为什么一组特定的权重会起作用。所以你只是写了一个你并不真正理解的函数,但是可以证明它是有效的。
想象一下,你的预测函数不是采用 “sqft” 和 “num-of-bedrooms” 这样的参数,而是接受一组数字。
假设每个数字代表安装在汽车顶部的摄像头拍摄的图像中一个像素的亮度。现在让我们假设,该函数不是输出一个名为“价格”的预测,而是输出一个名为“度”的预测来转动方向盘。那么你刚刚做了一个可以自动驾驶汽车的函数!
相当疯狂,不是吗?
第3步中,“尝试每个权重数字”是什么意思?
当然不可能去尝试所有可能的权重组合来找到最有效的组合。这真的需要花上很长时间,因为你永远也不会用尽所有的数字。
为了避免这种情况的发生,数学家们想出了许多聪明的方法,可以快速地找到合适的权重值而无需太多尝试。这里提供一种方法:
首先,写一个简单的方程来表示上面的第2步:
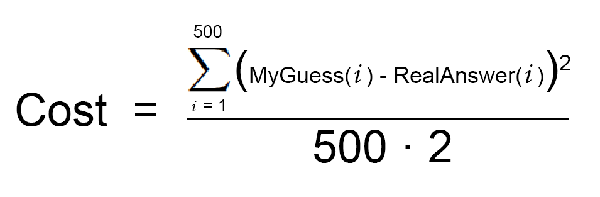
这是你的成本函数。
现在让我们重写一个完全相同的方程,但是使用一些机器学习的数学术语(你可以暂时忽略):

θ 表示当前权重,J(θ) 表示当前权重的成本。
这个方程表示我们的价格估计函数在我们目前设置的权重下的错误程度。
如果我们将 numberofbedroom 和 sqft 的成本函数的所有权重可能值绘制出来,我们会得到这样一个图形:
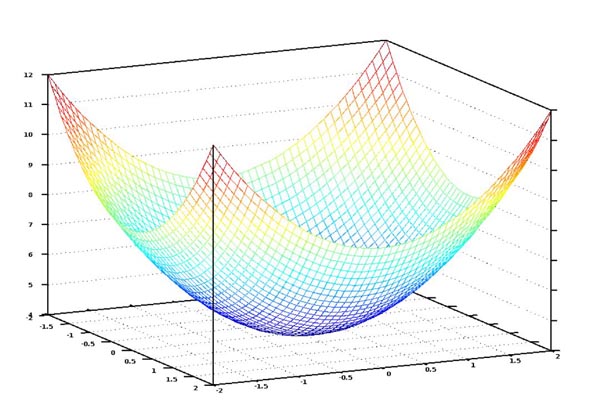
我们的成本函数图看起来像一个碗。纵轴代表成本。
在这张图中,蓝色的最低点就我们成本最低的地方,即函数误差值最小。最高点是我们错误值越大的地方。所以,如果我们能找到这个图形最低点的权重,我们就得到答案了!

所以我们只需要调整权重,在这个图上“下山”到最低点。如果我们不断地对权重进行小的调整,使其始终向最低点移动,我们最终就会不需要尝试太多权重的情况下到达最低点。
如果你还记得微积分的知识,你可能还记得如果对一个函数求导,会得到函数在任意点切线的斜率。换句话说,它告诉我们曲线上任意一点的下坡方向。我们可以用这些知识来走下坡。
因此,如果我们计算成本函数对每个权重的偏导数,我们就可以从每个权重中减去这个值。这将使我们离山脚更近一步。继续这样做,最终我们会到达山的底部,并为我们的权重找到最好的值。(如果不理解,别担心,继续读下去)。
这是一种为函数寻找最佳权重方法的高级总结,称为批量梯度下降(batch gradient descent)。当你使用机器学习库来解决实际问题时,所有这些计算都会为你完成。但是对正在发生的事情有一个好的了解仍然是有用的。
还跳过了什么内容呢?
我所描述的三步算法叫做多元线性回归(multivariate linear regression)。你正在估算一条贯穿你的所有家庭数据点的直线的方程。然后,根据房子在你的线上的位置,用这个方程来预测你以前从未见过的房子的销售价格。这是一个非常有用的主意,你可以用它来解决“真正的”问题。
虽然我向你展示的方法适用于简单的情况,但它并不适用于所有情况。其中一个原因是,房价并不总是简单到可以遵循一条连续的线。
但幸运的是,有很多方法可以解决这个问题。有许多其他的机器学习算法可以处理非线性数据(如神经网络(neural networks)或带内核的支持向量机(support vector machine, SVM)。也有一些更巧妙地使用线性回归的方法,允许更复杂的线被拟合。在所有情况下,找到最佳权重的基本思想仍然适用。
另外,我忽略了 过拟合(overfitting)的概念。一个简单的例子,有一组权重,它总是能够很好地预测原始数据集中房屋的价格,但实际上从未适用于任何不在原始数据集中的新房屋。但有一些方法可以解决这一问题(如正则化(regularization) 和使用交叉验证数据集(cross-validation)。学会如何处理这个问题是学习如何成功应用机器学习的关键部分。
换句话说,虽然基本概念相当简单,但是应用机器学习并获得有用的结果需要一些技巧和经验。但这是任何开发人员都可以学习的技能!
机器学习有魔法吗?
一旦你开始发现机器学习技术很容易应用到看起来很难解决的问题上(比如手写识别),你就会开始感觉到你可以用机器学习来解决任何问题,只要你有足够的数据就可以得到答案。只需要输入数据,然后看着电脑神奇地计算出与数据相符的方程!
但重要的是要记住,机器学习只有在问题确实可以用现有的数据解决的情况下才有效。
例如,如果你建立一个模型,根据每套房子里盆栽植物的类型来预测房价,那么这个模型永远不会奏效。每套房子里的盆栽植物和房子的售价之间没有任何关系。因此,无论如何努力,计算机永远无法推断出两者之间的关系。

只能够为实际存在关系的模型建模。所以记住,如果人类专家不能用这些数据来手动解决这个问题,那么计算机可能也不能。更应该关注的是那些人类可以解决的问题,如果计算机能够更快地解决,就太棒了。
如何深入了解机器学习?
在我看来,目前机器学习最大的问题是它主要存在在学术界和商业研究团体的世界里。对于那些想要在不成为专家的情况下而能广泛理解机器学习的人来说,并没有很多容易理解的材料。但是这方面每天都在进步。
如果你想深入了解,吴恩达(Andrew Ng)在 Coursera 上开设的免费机器学习课程是非常棒的。我强烈推荐。它应该对任何拥有计算机科学学位并且只记得很少数学知识的人都是容易理解的。
作者:佚名_人工智能与大数据技术
原文链接:https://mp.weixin.qq.com/s/6Sef99jFz1eGdqRLOX5JpQ
转载请注明:www.ainoob.cn » 机器学习爱好者必读的入门指南






