即将开播:4月29日,民生银行郭庆谈商业银行金融科技赋能的探索与实践
本文转载自公众号“读芯术”(ID:AI_Discovery)
当你踏上机器学习之旅时,搞清楚监督学习和无监督学习是你应该做的第一件事。而对于新手而言,“监督学习和无监督学习有什么区别?”,是最为常见不过的问题。
其答案在于理解机器学习算法的本质。如果没有明确监督学习和无监督学习之间的区别,你的学习之旅将无法前行。
如果sSDBQIF不了解线性回归、逻辑回归、聚类、神经网络等算法的适用范围,就没法直接进入模型构建阶段。
如果不知道机器学习算法的目标是什么,就无法建立一个精确的模型。这就是监督学习和无监督学习的由来。
本文就将帮你解决这个问题,再友情奉送另一个关键问题:如何决定何时使用监督学习或无监督学习?
什么是监督学习?
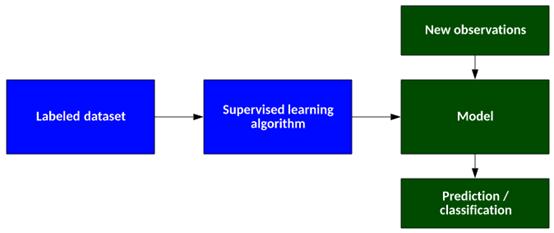
在监督学习中,计算机通过示例学习。它从过去的数据中学习,并将学习的结果应用到当前的数据中,以预测未来的事件。在这种情况下,输入和期望的输出数据都有助于预测未来事件。
为了准确预测,将输入数据标记为正确答案。
监督机器学习分类
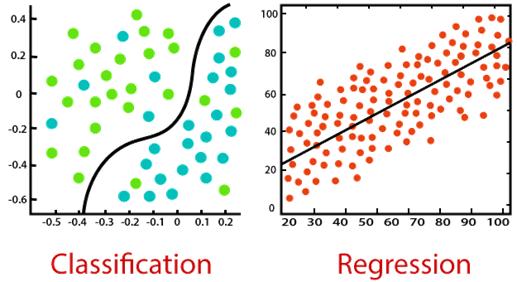
重要的是,要记住:所有监督学习算法本质上都是复杂算法,分为分类或回归模型。
- 回归模型—回归模型用于输出变量为实际值的问题,例如单一的数字、美元、薪水、体重或压力。它最常用于根据先前的观测数据来预测数值。一些比较常见的回归算法包括线性回归、逻辑回归、多项式回归和脊回归。
- 分类模型—分类模型用于可以对输出变量进行分类,例如“是”或“否”、“通过”或“失败”。分类模型用于预测数据的类别。现实生活中的例子包括垃圾邮件检测、情绪分析、考试记分卡预测等。
监督学习算法在现实生活中有一些非常实际的应用,包括:
- 文本分类
- 垃圾邮件检测
- 天气预报
- 根据当前市场价格预测房价
- 股票价格预测等
- 人脸识别
- 签名识别
- 客户发现
什么是无监督学习?
无监督学习是训练机器使用既未分类也未标记的数据的方法。这意味着无法提供训练数据,机器只能自行学习。机器必须能够对数据进行分类,而无需事先提供任何有关数据的信息。
其理念是先让计算机与大量变化的数据接触,并允许它从这些数据中学习,以提供以前未知的见解,并识别隐藏的模式。因此,无监督学习算法不一定有明确的结果。相反,它确定了与给定数据集不同或有趣之处。
计算机需要编程才能自学。计算机需要从结构化和非结构化数据中理解和提供见解。以下是无监督学习的准确说明:

无监督机器学习分类
- 聚类是最常见的无监督学习方法之一。聚类的方法包括将未标记的数据组织成类似的组,称为聚类。因此,聚类是相似数据项的集合。此处的主要目标是发现数据点中的相似性,并将相似的数据点分组到一个聚类中。
- 异常检测是识别与大多数数据显著不同的特殊项、事件或观测值的方法。通常在数据中寻找异常或异常值的原因在于它们是可疑的。异常检测常用于银行欺诈和医疗差错检测。

无监督学习算法的应用
无监督学习算法的一些实际应用包括:
- 恶意软件检测
- 数据输入过程中人为错误识别
- 进行准确的购物篮分析等
- 欺诈检测
应该什么时候选择监督学习或无监督学习?
在制造业中,有很多因素影响哪种机器学习方法最适合任何给定的任务。而且,由于每个机器学习问题的独特性,决定使用哪种技术是一个复杂的过程。
一般来说,选择正确机器学习方法的一个好策略是:
- 评估数据。标记与否?是否有专家知识支持附加标记?这将有助于确定是否应使用监督、无监督、半监督或强化的学习方法。
- 审查可用的算法,其可能适合维度问题(特征、属性或特征的数量)。候选算法应适合于整个数据量以及其结构。
- 研究成功案例,关于类似问题上应用的算法类型。
- 定义目标。被定义的问题是否反复出现?是否期望算法能预测新的问题?

监督学习和无监督学习是机器学习领域中的关键概念,这应该是你开始学习机器学习的第一课,一定要理解透彻呀!

AIX人工智能社区

作者:读芯术_读芯术
原文链接:https://www.toutiao.com/i6820687480707088903/
转载请注明:www.ainoob.cn » 监督学习or无监督学习?这个问题必须搞清楚




