即将开播:4月29日,民生银行郭庆谈商业银行金融科技赋能的探索与实践
预测销售是机器学习(ML)的常见且必不可少的用途。预测销售可用于确定基准并确定新计划的增量影响,根据预期需求规划资源以及规划未来预算。在本文中,我将展示如何实现5种不同的ML模型来预测销售。
初期准备
首先我们先加载数据并将其转换为一个结构,然后将其用于每个模型。以原始格式,每一行数据代表十个商店中一天的销售额。我们的目标是预测月度销售额,因此我们将首先将所有商店和天数合并为月度总销售额。
- def load_data():
- return pd.read_csv('D:\Jupyter\dataset\demand-forecasting-kernels-only/train.csv')
- def monthly_sales(data):
- monthly_data = data.copy()
- monthly_datamonthly_data.date = monthly_data.date.apply(lambda x: str(x)[:-3])
- monthly_datamonthly_data = monthly_data.groupby('date')['sales'].sum().reset_index()
- monthly_data.date = pd.to_datetime(monthly_data.date)
- return monthly_data
- monthly_df = monthly_sales(sales_data)
- monthly_df.head()
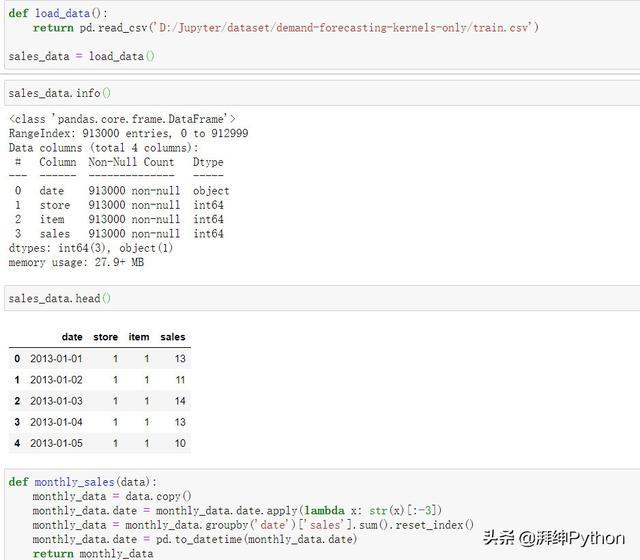
在我们的新数据框中,每一行现在代表所有商店在给定月份的总销售额。
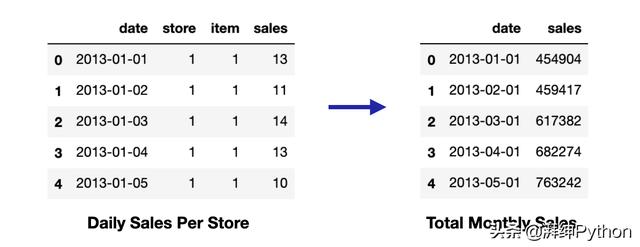
如果我们绘制随时间变化的每月总销售量,我们会看到平均每月销售量随时间增加,这意味着我们的数据不是固定的。为了使其平稳,我们将计算每月销售额之间的差异,并将其作为新列添加到我们的数据框中。
- def get_diff(data):
- data['sales_diff'] = data.sales.diff()
- datadata = data.dropna()
- data.to_csv('D:/Jupyter/dataset/demand-forecasting-kernels-only/stationary_df.csv')
- return data
- stationary_df = get_diff(monthly_df)

下面是差异转换前后数据外观的直观表示:
比较差异前后的平稳性
现在,我们的数据代表了每月的销售额,并且已经将其转换为固定值,接下来我们将为不同的模型类型设置数据。为此,我们将定义两种不同的结构:一种将用于ARIMA建模,另一种将用于其余的模型。
对于我们的Arima模型,我们只需要一个日期时间索引和因变量(销售额差异)列。
- def generate_arima_data(data):
- dt_data = data.set_index('date').drop('sales', axis=1)
- dt_data.dropna(axis=0)
- dt_data.to_csv('D:/Jupyter/dataset/demand-forecasting-kernels-only/arima_df.csv')
- return dt_data
- arima_datetime = generate_arima_data(stationary_df)
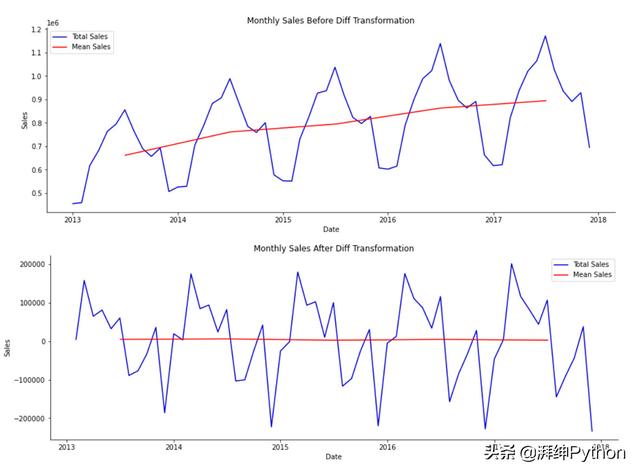
对于其他模型,我们将创建一个新的数据框,其中每个特征代表上个月的销售额。为了确定在我们的特征集中包含多少个月,我们将观察自相关和部分自相关图,并在ARIMA建模中使用选择滞后时间的规则。这样,我们就可以为我们的ARIMA和回归模型保持一致的回顾周期。
自相关和局部自相关图
基于上述情况,我们将选择回溯期为12个月。因此,我们将生成一个包含13列的数据框,12个月每个月为1列,而我们的因变量即销售额差异列为第1列。
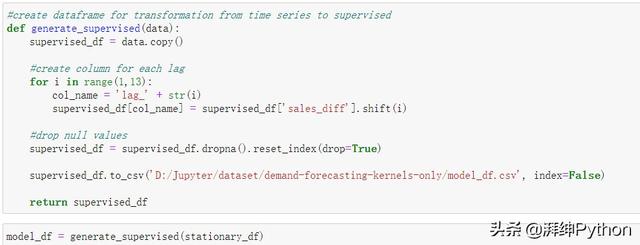
- def generate_supervised(data):
- supervised_df = data.copy()
- #create column for each lag
- for i in range(1,13):
- col_name = 'lag_' + str(i)
- supervised_df[col_name] = supervised_df['sales_diff'].shift(i)
- #drop null values
- supervised_dfsupervised_df = supervised_df.dropna().reset_index(drop=True)
- supervised_df.to_csv('D:/Jupyter/dataset/demand-forecasting-kernels-only/model_df.csv', index=False)
- return supervised_df
- model_df = generate_supervised(stationary_df)
现在我们有两个独立的数据结构,一个是Arima结构,它包含一个datetime索引,另一个是监督结构,它包含滞后时间特征。
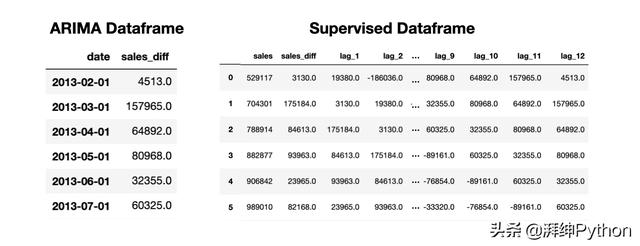
ARIMA和受监督的数据框用于销售预测
建模
为了创建和评估所有的模型,我们使用了一系列执行以下函数的辅助函数。
- 训练、测试、拆分:我们将数据分开,使过去的12个月成为测试集的一部分,其余数据用于训练我们的模型
- 缩放数据:使用最小-最大缩放器,我们将缩放数据,以便所有变量都在-1到1的范围内
- 反向缩放:运行模型后,我们将使用此辅助函数来反转步骤2的缩放
- 创建一个预测数据框:生成一个数据框,其中包括在测试集中捕获的实际销售额和模型的预测结果,以便我们能够量化我们的成功
- 对模型评分:这个辅助函数将保存我们预测的均方根误差(RMSE)和均值绝对误差(MAE),以比较五个模型的性能
1. 回归模型:线性回归,随机森林回归,XGBoost
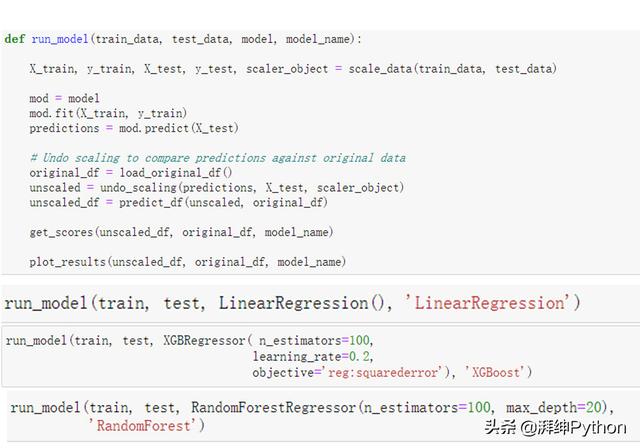
对于我们的回归模型,我们可以使用scikit-learn库的fit-predict结构。因此,我们可以建立一个基础建模结构,我们将针对每个模型进行调用。下面的函数调用上面概述的许多辅助函数来拆分数据,运行模型并输出RMSE和MAE分数。
- def regressive_model(train_data, test_data, model, model_name):
- # Call helper functions to create X & y and scale data
- X_train, y_train, X_test, y_test, scaler_object =
- scale_data(train_data, test_data)
- # Run regression model
- mod = model
- mod.fit(X_train, y_train)
- predictions = mod.predict(X_test)
- # Call helper functions to undo scaling & create prediction df
- original_df = pd.read_csv('D:/Jupyter/dataset/demand-forecasting-kernels-only/train.csv')
- unscaled = undo_scaling(predictions, X_test, scaler_object)
- unscaled_df = predict_df(unscaled, original_df)
- # Call helper functions to print scores and plot results
- get_scores(unscaled_df, original_df, model_name)
- plot_results(unscaled_df, original_df, model_name)
- # Separate data into train and test sets
- train, test = tts(model_df)
- # Call model frame work for linear regression
- regressive_model(train, test, LinearRegression(),'LinearRegression')
- # Call model frame work for random forest regressor
- regressive_model(train, test,
- RandomForestRegressor(n_estimators=100,
- max_depth=20),
- 'RandomForest')
- # Call model frame work for XGBoost
- regressive_model(train, test, XGBRegressor(n_estimators=100,
- learning_rate=0.2),
- 'XGBoost')
下面的输出显示了每个回归模型的预测(红色)覆盖在实际销售(蓝色)之上。虽然结果看起来很相似,但细微的差别相当于几千美元的销售额,我们将在下面的比较部分中看到。

2. 长短期记忆(LSTM)
LSTM是一种递归神经网络,对于使用顺序数据进行预测特别有用。为此,我们将使用非常简单的LSTM。为了提高准确性,可以添加周期性特征和附加模型复杂性。
- def lstm_model(train_data, test_data):
- X_train, y_train, X_test, y_test, scaler_object = scale_data(train_data, test_data)
- X_trainX_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1])
- X_testX_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1])
- model = Sequential()
- model.add(LSTM(4, batch_input_shape=(1, X_train.shape[1], X_train.shape[2]),
- stateful=True))
- model.add(Dense(1))
- model.add(Dense(1))
- model.compile(loss='mean_squared_error', optimizer='adam')
- model.fit(X_train, y_train, epochs=200, batch_size=1, verbose=1,
- shuffle=False)
- predictions = model.predict(X_test,batch_size=1)
- original_df = load_original_df()
- unscaled = undo_scaling(predictions, X_test, scaler_object, lstm=True)
- unscaled_df = predict_df(unscaled, original_df)
- get_scores(unscaled_df, original_df, 'LSTM')
- plot_results(unscaled_df, original_df, 'LSTM')
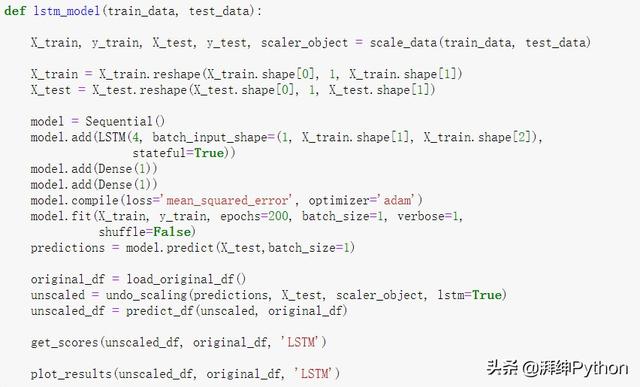
生成的图看起来与上面的三个回归图相似,因此我们将继续比较结果,直到我们看到下面的误差为止。
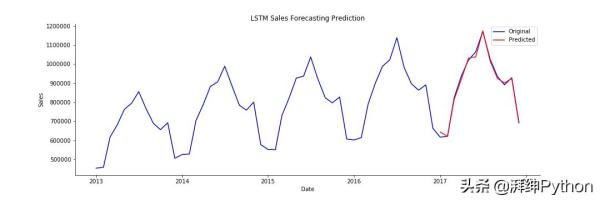
LSTM模型预测与实际销售额
3. ARIMA
ARIMA模型看起来与上面的模型略有不同。我们使用statsmodels SARIMAX软件包来训练模型并生成动态预测。SARIMA模型分为几个部分。
- AR:表示为p,是自回归模型
- I:用d表示,是微分项
- MA:表示为q,是移动平均模型
- S:使我们能够添加周期性成分
在下面的代码中,我们定义我们的模型,然后对数据的最后12个月进行动态预测。对于标准的非动态预测,下个月的预测是使用前几个月的实际销售额进行的。相反,对于动态预测,使用前几个月的预测销售额进行下个月的预测。
- def lstm_model(train_data, test_data):
- X_train, y_train, X_test, y_test, scaler_object = scale_data(train_data, test_data)
- X_trainX_train = X_train.reshape(X_train.shape[0], 1, X_train.shape[1])
- X_testX_test = X_test.reshape(X_test.shape[0], 1, X_test.shape[1])
- model = Sequential()
- model.add(LSTM(4, batch_input_shape=(1, X_train.shape[1], X_train.shape[2]),
- stateful=True))
- model.add(Dense(1))
- model.add(Dense(1))
- model.compile(loss='mean_squared_error', optimizer='adam')
- model.fit(X_train, y_train, epochs=200, batch_size=1, verbose=1,
- shuffle=False)
- predictions = model.predict(X_test,batch_size=1)
- original_df = load_original_df()
- unscaled = undo_scaling(predictions, X_test, scaler_object, lstm=True)
- unscaled_df = predict_df(unscaled, original_df)
- get_scores(unscaled_df, original_df, 'LSTM')
- plot_results(unscaled_df, original_df, 'LSTM')
同样,结果看起来还不错。我们将在下面进一步进行挖掘。
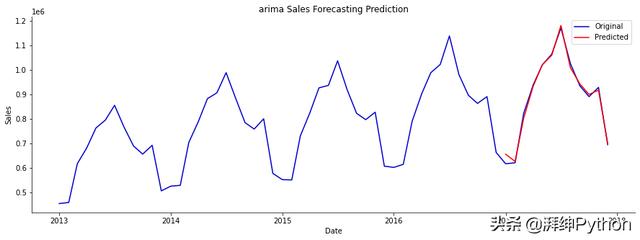
ARIMA模型预测与实际销售额
比较模型
为了比较模型性能,我们将查看均方根误差(RMSE)和均值绝对误差(MAE)。这些指标通常都用于比较模型性能,但是它们的直觉和数学含义略有不同。
- MAE:均值绝对误差告诉我们,我们的预测与真实值之间的距离。在这种情况下,所有误差的权重都相同。
- RMSE:我们通过取所有平方误差之和的平方根来计算RMSE。当我们平方时,较大的误差对整体误差有较大的影响,而较小的误差对整体误差没有太大的影响。
从上面的辅助函数中,我们使用get_scores计算每个模型的RMSE和MAE分数。这些分数保存在字典中并保存起来。为了进行比较,我们将把字典转换成Pandas数据框并绘制结果。
- def create_results_df():
- results_dict = pickle.load(open("model_scores.p", "rb"))
- results_dict.update(pickle.load(open("arima_model_scores.p", "rb")))
- restults_df = pd.DataFrame.from_dict(results_dict, orient='index',
- columns=['RMSE', 'MAE','R2'])
- restults_dfrestults_df = restults_df.sort_values(by='RMSE', ascending=False).reset_index()
- return restults_df
- results = create_results_df()
这为我们提供了以下数据框。
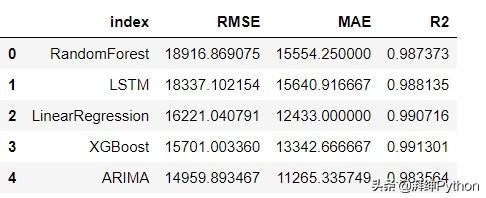
我们可以看到,尽管我们的模型输出在上图中看起来相似,但它们的准确度确实有所不同。下面是可以帮助我们看到差异的视觉效果。
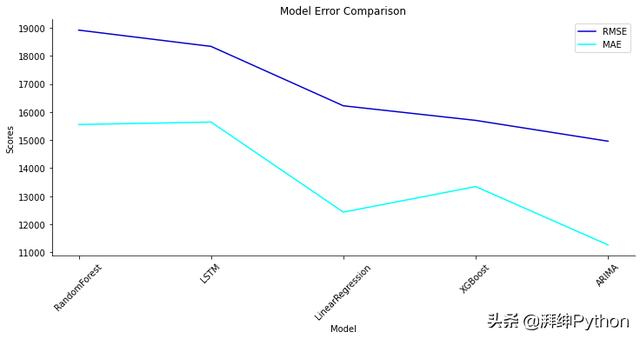
比较模型性能
结论
我们看到的是,总体而言,XGBoost模型具有最佳性能,紧随其后的是ARIMA和LSTM模型。需要注意的是,以上所有模型都是以其最基本的形式衍生的,以演示如何将其用于销售预测。仅对模型进行了微调,以最大程度地减少复杂性。例如,LSTM可以具有许多其他节点和层以提高性能。
要确定哪种模型适合您的用例,应考虑以下内容:
- 模型复杂度与可解释性的程度。
- 可以调整模型,并可以对函数进行设计以包括周期性信息,节假日,周末等。
- 了解如何使用结果以及如何输入数据来更新模型。
- 使用交叉验证或类似技术来调整模型,以避免数据过度拟合。
作者:湃绅Python_今日头条
原文链接:https://www.toutiao.com/a6819185785871270411/
转载请注明:www.ainoob.cn » 5种用于预测销售的机器学习技术






